Run-length encoding in OMF object files
The Relocatable Object Module Format (OMF) is a file format designed by Intel for their 80×86 processors. It was a commonly used output format of 16-bit DOS compilers and assemblers usually with the extension .OBJ.
The file format consists of a series of records. Here we will concentrate on the Logical Iterated Data Record (LIDATA) which has an interesting method of run-length encoding data. The record consists of a data block. A data block contains a repeat count, a block count, and data. The repeat count specifies how many times the data in the data block should be repeated. The data can consist of either a number of more data blocks as specified by block count, or if block count is zero, a series of up to 255 data bytes. We can illustrate this recursive scheme with data blocks nested within another data block as a box which can contain either more boxes or some text. The repeat count of each box is shown in the upper left corner of the box.
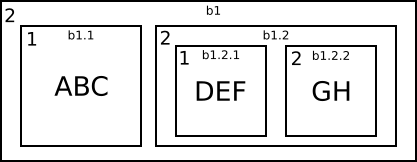
In this example we have a box which contains two more boxes, and the second of these does itself contain two more boxes. We can label the boxes in the following way. The outermost box we call b1, the two boxes inside b1 we call b1.1 and b1.2. The box b1.2 contains two more boxes which we call b1.2.1 and b1.2.2. Now, to see what final string this scheme will produce we process the boxes from left to right and concatenate the strings together. The box b1.1 will produce the string “ABC” repeated 1 time so the string of b1.1 is “ABC”. The next box, b1.2 contains two boxes, b1.2.1 which produces the string “DEF” and b1.2.2 which produces “GHGH”. Putting these together and then repeating twice we get that b1.2 produces the string “DEFGHGHDEFGHGH”. Putting b1.1 and b1.2 together we get the string “ABCDEFGHGHDEFGHGH”. The box b1 contains a repeat count of two so the final string will be “ABCDEFGHGHDEFGHGHABCDEFGHGHDEFGHGH”. We can express this more simply using algebra on strings like in the Python language as 2*(1 * “ABC” + 2*(1 * “DEF” + 2 * “GH”)).
The actual data block in the file has the following format:

Repeat Count is a 16-bit value and determines how many times the Data field is repeated.
Block Count is a 16-bit value which determines how the Data field is interpreted. A value of 0 indicates that the Data field contains a 1-byte count value followed by count data bytes. The data bytes will be repeated as many times as specified by the repeat count. If the block count field is not zero it indicates that the data field is composed of one or more data blocks, as many as indicated by the block count value. The data blocks considered as one unit is repeated as specified by the repeat count.
This format can be a very compact way of representing repetitive data. For example consider the string 300*(100 * “ABC” + 100*(20 * “DEF” + 30 * “GHI”)) in Python notation. Illustrated with boxes it would look like this:
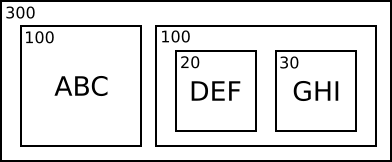
The length of this string is about 4.6 million bytes. As a data block in an LIDATA record this would take up 4 bytes for each of the five data blocks and 4 bytes for each of the 3 strings which gives a total of 4*5 + 4*3 = 32 bytes! Quite the saving. As a comparison, zip compresses this string to 36k, 7-zip does a lot better with 3.5k.
Sidenote: Assemblers like MASM and TASM include a DUP command which can save you a lot of typing. To declare an array of 100 bytes with the value 1 you can write DB 100 DUP(1). I haven’t investigated if the DUP command can be nested or if when using it the assembler will make use of the LIDATA nested block structure. If so, was the DUP command introduced to take advantage of the LIDATA record or was the LIDATA record created based on the DUP command? If someone knows the history, please leave a comment!